AI コーディングエージェントの登場により、エディタで直にコードをいじらずともプログラム開発が可能になった。最近はこれらエージェントをブラウザ上からも使えるようになった。たとえばClaude Code on the webがそのようなエージェントの一例だ。
これを使えばスマホでどこでもゲームが開発できるのでは?そう考えて作ったプロンプトやツールを、以下のリポジトリに置いた。
このリポジトリは 2024/3 から作っており、ここで LLM を使ったワンボタンアクションミニゲーム作りをいろいろ試行錯誤している。Claude のチャットインタフェースから、Cursor の IDE、CLI の Claude Code など、いろいろな環境を渡り歩きながら、試行錯誤を続けている。
ある意味この記事はこの試みの第 5 回である。
スマホでブラウザゲーム開発のワークフロー
Claude Code on the web は GitHub と連携して動作する。あるリポジトリを指定してそれに対してチャットを行うと、新たなブランチが作成され、そのブランチに対してエージェントが継続的に作業が行えるようになる。そのブランチでの作業が終わったら、プルリクエストを作成し、できた成果物を main/master に取り込む。
ブラウザゲーム開発であれば、この作業中に作成したゲームをブラウザ上で確認したい。だがこれら作業は個別のコンテナ環境内で行われ、そのネットワークアクセスはネットワークポリシーで管理されている。そのため、この環境で Web サーバを立ててゲームを動かしそれを外部から確認する、などはできない。
そこで役立つのがNetlifyなどのデプロイサービスだ。Netlify は GitHub と連携し、特定リポジトリのブランチの成果物を Web にデプロイすることができる。これを使えば、ブランチで作業中の内容をブラウザ上で確認できる。
これらを使った結果のワークフローは、例えば以下のようになる:
- ブラウザ上でコード編集:Claude Code との対話によりゲームロジックを実装
- コミット&プッシュ:エージェントがGitHubブランチへ変更を反映
- 自動ビルド&デプロイ:Netlifyが自動的にビルド、ブランチごとのプレビューURLを生成
- モバイルでの即座確認:生成された URL にアクセス、動作確認
- フィードバック&改善:モバイルでの体験をもとに、再びブラウザ上でエージェントと対話して改善
「〇〇ゲームを作って」ではうまくいかない問題
ただ現状のコーディングエージェントはそんなにゲーム作りが得意ではない。単に「〇〇ゲームを作って」と丸投げすると、ゲームとして成り立ってない謎の挙動をするものが返ってくることがままある。そんなものをスマホ上からチャット UI だけで修正し続けるのはかなりの苦行だ。できれば最初からある程度ちゃんと遊べるゲームになっていて欲しい。
なのでブランチ元のリポジトリで、コーディングエージェント向けのゲーム開発指針をある程度プロンプトやツールで補強しておいた方が良い。今回は以下のようなアプローチを取った。
ゲームメカニクスタグのランダム選出による元ネタの生成
前に自作ゲームがどういったメカニクス、例えばプレイヤーの動き方や得点の方法などから構成されているかをタグとして整理した。
これは LLM が新しいゲームを生成するための仕組みでもあった。
今回はこれらのタグをスクリプトでランダムに選択し、それらを新たなゲームの発想の元ネタとした。
また、これらのタグがどのように実現されているかを、対応するゲームコードと紐づけることで示している。これは、そのメカニズムをどう実装すれば良いかを、エージェントが正しく把握するのにある程度役立っている、はずである。
構造化されたゲーム設計・実装プロセス
上記タグ選択に続き、以下の 6 つのフェーズでゲーム設計・実装は行われる。
Phase 0: タグ選択と初期検証 ↓ ✅ タグ承認 Phase 1: 問題-解決の構造化 ↓ ✅ ロジック検証 Phase 2: 創造的統合と新規性保証 ↓ ✅ 創造性確認 Phase 3: 実装とプロトタイピング ↓ ✅ 基本動作確認 Phase 4: 検証とバランス調整 ↓ ✅ バランス承認 Phase 5: 最終検証と完成承認 ↓ ✅ 最終承認 完成
各フェーズには明確な完了基準と人間の承認ポイントが設定されている。これにより AI が独走することなく、人間の意図が各段階で反映される。
Phase 2 の新規性保証はタグの組み合わせが既存ゲームとどの程度異なるかをスクリプトでチェックしたり、Phase 4 のバランス調整は理想的なボタン入力を遺伝的アルゴリズムで生成・動作確認しその結果に応じてゲーム内パラメタを自動調整したり、みたいな機構もいれているのだが……正直これらがどのくらいうまく機能しているのかはよく分からない。
どちらかというと、途中の人間の承認ポイントで、人間が適切に方向転換させることで、遊べるゲームへの調整が簡単に行えることが、このプロセスにおいては重要である。そのためにも、エージェントに適切な完了基準を示し、あいまいな状態でのフェーズ完了を許さないことが大事だ。
で、実際にどんなゲームができるのか
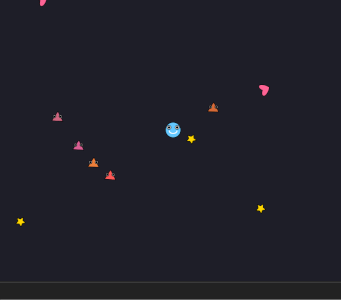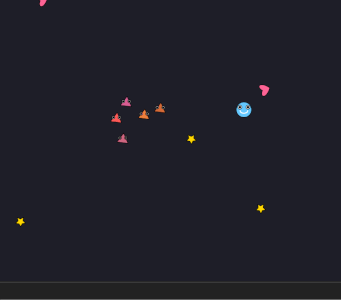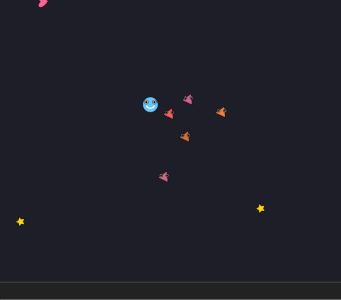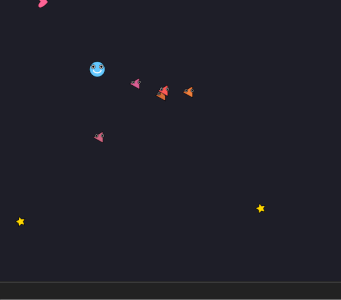
先ほどのリポジトリのゲーム例一覧にある 4 つのゲーム(MAGNETIC PENDULUM、RICOCHET PINS、ARC SPIN、WIND RANG)ができたゲームの例だ。すごい独創的かと言われるとそうでもないが、ありきたりでもなく、バランスが取れているゲームがある程度できている。
これらゲームの開発が、実際上記のチャットでのフローで完結しているかというと、そうではなく、プルリクエストを受け付けてから PC 上である程度ソースコードを調整して最終バランス調整を行っている。それでもゲームのベースメカニクス実装はスマホ上で完了させることができ、これはなかなか良い開発体験だった。
ゲーム開発の楽しさは、エディタでコードを書いてゲームを実現することだけでなく、こういうメカニクスはどうか?というアイデアを試し、遊び、改良するサイクルにもある。コーディングエージェントは、そのサイクルを劇的に加速する。スマホという制約された環境でさえ、思いついたメカニクスを30分で形にできる。これは、いわゆる創作の民主化と呼ばれる動きの、ゲーム版の一例かもしれない。
いつでも、どこでも、だれでも、ゲームのアイデアを形にできる。そんなゲーム&ウォッチ感覚の開発体験が、選択肢の一つとして現実的になりつつある。